Prelude
At my work, I had an opportunity to start an experiment: Writing a single parser implementation in Rust for the new Gutenberg post format, bound to many platforms and environments.

Gutenberg's logo.
This series of posts is about those bindings, and explains how to send Rust beyond earth, into many different galaxies.
The Gutenberg post format
Let's introduce quickly what Gutenberg is, and why a new post format. If you want an in-depth presentation, I highly recommend to read The Language of Gutenberg. Note that this is not required for the reader to understand the Gutenberg post format.
Gutenberg is the next WordPress editor. It is a little revolution on its own. The features it unlocks are very powerful.
The editor will create a new page- and post-building experience that makes writing rich posts effortless, and has “blocks” to make it easy what today might take shortcodes, custom HTML, or “mystery meat” embed discovery. — Matt Mullenweg
The format of a blog post was HTML. And it continues to be. However, another semantics layer is added through annotations. Annotations are written in comments and borrow the XML syntax, e.g.:
<!-- wp:ns/block-name {"attributes": "as JSON"} -->
phrase
<!-- /wp:ns/block-name -->
The Gutenberg format provides 2 constructions: Block, and Phrase. The example above contains both: There is a block wrapping a phrase. A phrase is basically anything that is not a block. Let's describe the example:
- It starts with an annotation (
<!-- … -->), - The
wp:is mandatory to represent a Gutenberg block, - It is followed by a fully qualified block name, which is a pair of an
optional namespace (here sets to
ns, defaults tocore) and a block name (here sets toblock-name), separated by a slash, - A block has optional attributes encoded as a JSON object (see RFC 7159, Section 4, Objects),
- Finally, a block has optional children, i.e. an heterogeneous
collection of blocks or phrases. In the example above, there is one
child that is the phrase
<p>phrase</p>. And the following example below shows a block with no child:
<!-- wp:ns/block-name {"attributes": "as JSON"} /-->
The complete grammar can be found in the parser's documentation.
Finally, the parser is used on the editor side, not on the rendering side. Once rendered, the blog post is a regular HTML file. Some blocks are dynamics though, but this is another topic.
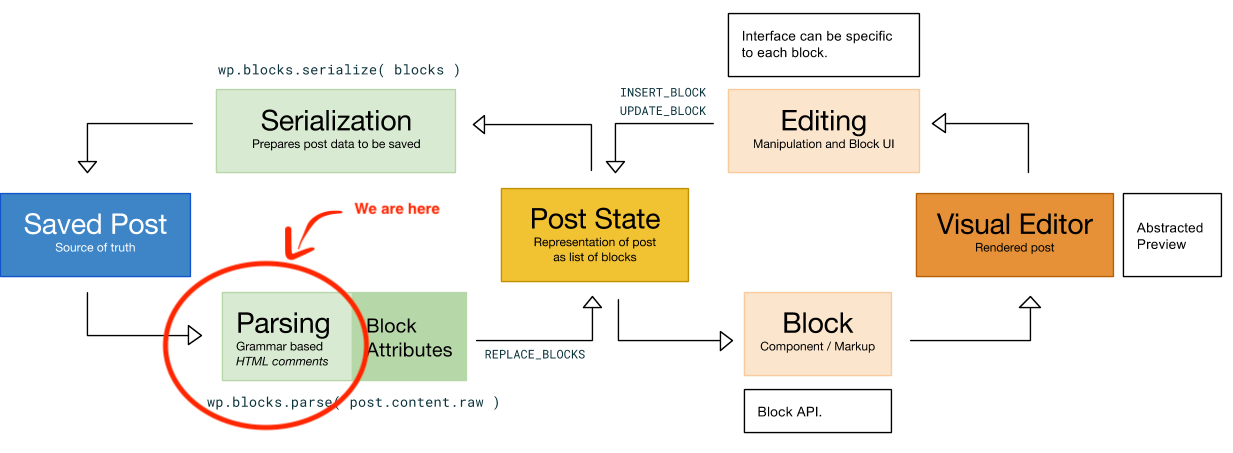
The logic flow of the editor (How Little Blocks Work).
The grammar is relatively small. The challenges are however to be as much performant and memory efficient as possible on many platforms. Some posts can reach megabytes, and we don't want the parser to be the bottleneck. Even if it is used when creating the post state (cf. the schema above), we have measured several seconds to load some posts. Time during which the user is blocked, and waits, or see an error. In other scenarii, we have hit memory limit of the language's virtual machines.
Hence this experimental project! The current parsers are written in
JavaScript (with PEG.js) and in PHP (with
phpegjs). This Rust project
proposes a parser written in Rust, that can run in the JavaScript and in
the PHP virtual machines, and on many other platforms. Let's try to be
very performant and memory efficient!
Why Rust?
That's an excellent question! Thanks for asking. I can summarize my choice with a bullet list:
- It is fast, and we need speed,
- It is memory safe, and also memory efficient,
- No garbage collector, which simplifies memory management across environments,
- It can expose a C API (with Foreign Function Interface, FFI), which eases the integration into multiple environments,
- It compiles to many targets,
- Because I love it.
One of the goal of the experimentation is to maintain a single implementation (maybe the future reference implementation) with multiple bindings.
The parser
The parser is written in Rust. It relies on the fabulous nom library.

nom will happily take a byte out of your files 🙂
The source code is available in the src/ directory in the
repository. It is very
small and fun to read.
The parser produces an Abstract Syntax Tree (AST) of the grammar, where nodes of the tree are defined as:
That's all! We find again the block name, the attributes and the
children, and the phrase. Block children are defined as a collection of
node, this is recursive. Input<'a> is defined as &'a [u8], i.e. a
slice of bytes.
The main parser entry is the root
function.
It represents the axiom of the grammar, and is defined as:
;
So the parser returns a collection of nodes in the best case. Here is an simple example:
use ;
let input = &b"<!-- wp:foo {\"bar\": true} /-->";
let output = Ok;
assert_eq!;
The root function and the AST will be the items we are going to use
and manipulate in the bindings. The internal items of the parser will
stay private.
Bindings

From now, our goal is to expose the root function and the Node enum
in different platforms or environments. Ready?
3… 2… 1… lift-off!